
 020—85220049
020—85220050
020—85220049
020—85220050
EMBA知行讲堂第81期如期结束!
发布人:凌子山 发布时间:2025-04-18 点击次数:10
4月18日,EMBA知行讲堂第81期顺利举行。本期讲座邀请到暨南大学信息科学与技术学院教授邓玉辉作为主讲嘉宾,针对人工智能的使用热潮提出冷思考。人工智能生成和决策的原理是什么?基于该原理,人工智能在工作中又会存在怎样的问题?邓玉辉从信息科技的角度拆解人工智能,运用生动易懂的比喻,为同学们带来深入浅出的专业讲解。

主讲嘉宾
邓玉辉,暨南大学信息科学与技术学院教授、博士生导师。先后学习工作于华中科技大学,英国Cranfield University和国际存储系统公司EMC;先后担任数据管理、云计算、人工智能领域重要机构工程师/研究员;主持国家重点研发计划课题等项目30 余项;拥有发明专利 50 余件;发表权威国际期刊和会议论文150余篇。
讲座伊始,邓玉辉运用类比向同学们解释人工智能的基本原理。将“经验”归纳成“规律”,依据“规律”,人的大脑能够在遇到新问题时较为准确地预测未来;而将“历史数据”训练成“模型”,凭借“模型”,人工智能能够在输入新数据后推测未知属性。他指出,人工智能的三个关键要素为算法、数据和算力。

接着,邓玉辉介绍人工智能、机器学习、神经网络和深度学习各自的含义以及四者之间的关系。机器学习利用算法对数据进行分析和学习,以解决特定问题,包括分类、聚类、回归和降维等方法。在此基础上,神经网络加入激活函数增加非线性因素,能够解决非线性问题。深度神经网络是层数比较多的神经网络,而深度学习就是使用了深度神经网络的机器学习。
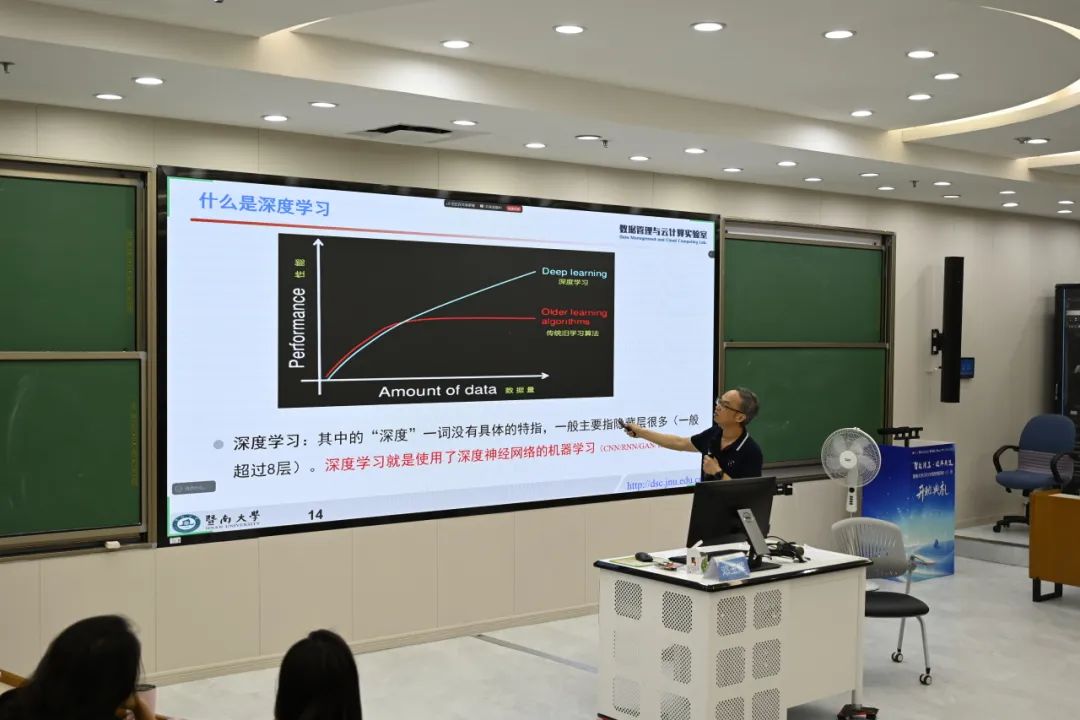
相比传统机器学习,深度学习没有瓶颈期,其性能会一直随数据量增大而增强。
随后,邓玉辉提出“打标签”概念。在人工智能领域,“打标签”指的是对数据集中的每个样本进行分类或标注的过程。此过程通常涉及将数据项(如文本、图像、音频等)分配到预定义的类别中,以便模型学习识别和分类新的、未见过的数据。人工智能训练师的核心工作就是给数据打高质量标签:将不同类型数据统一表示为向量,根据区分的需要给数据打多维标签,从而实现区分。由于深度学习模型精度对“标注”过的数据的量有很高要求,现今,“打标签”工作已经产业化。数据标注非常耗费人力物力,正所谓“人工智能,有多少人工,就有多少智能”。十年间,人工智能急速发展,从决策式转为生成式。2020年,OpenAI提出Scaling law,指出大模型的最终性能主要与模型参数量、训练数据量和计算量三者的大小相关,仅仅增加模型规模和训练数据,就能显著提升人工智能能力,而无需取得根本性的算法突破。

高质量标注数据的量随时间的增加使得人工智能具有多个领域的知识储备和多个维度的工作能力,生成式AI的应用场景越来越丰富。而与此同时,人工智能“以数据为基本”这一事实不可避免地导致其生成动作依据概率而非实际,其生成内容可能带有幻觉和偏见。

此外,人工智能的实际应用面临多方面风险。
(1)相较人力,使用AI编写恶意的网络攻击代码更为高效,将会降低黑客的门槛,增加网络安全风险。
(2)用户输入的数据可能被用于改进AI模型,意味着用户隐私、用户知识成果遭到泄露。
(3)AI生成内容过程中可能会不经授权使用受保护的文本、视频或代码,既侵犯了原创作者的知识产权,也让AI的使用者卷入法律纠纷。
(4)攻击者可能通过注入恶意样本或修改数据标签实现对AI模型的操控,模型的训练阶段、推理阶段以及用户对话都是潜在数据投毒点。
(5)大型语言模型能够通过逆向重构工程恢复底层训练数据中的敏感或隐私信息。
(6)攻击者能够通过改换措辞,引导AI模型违反自身编程限制对敏感问题做出回答,实现越狱。
科技一直是双刃剑。人工智能热潮下的一系列冷思考提醒着人们要在使用中保持独立思考。讲座末尾,邓玉辉希望同学们能够在认识人工智能技术两面性的基础上积极探索企业智能化部署的管理办法,做到让人工智能“为我所用”!
